
시작하며
⌜빅데이터를 지탱하는 기술⌟은 일명 ‘빅지기’로 불리며 오픈 채팅방 등에서 데이터 엔지니어링 입문용으로 많이 추천되는 책이다. 몇 년 전 취준생일 때 한 번 읽고 책장에 꽂아두기만 했는데, 최근에 다시 꺼내어 조금씩 곱씹어가며 읽어보니 예전과는 또 다른 재미가 있었다.
-
거시적인 관점에서 머릿속의 개념들이 체계가 잡히는 느낌이 들었다.
마이데이터업무를 시작하고 만 1년 반이 지난 지금에서야 기존의 레거시 아키텍처 + 연관 금융 인증 및 중계시스템 + 사업(비즈니스)이 어느 정도 파악이 되었는데, 거대한 아키텍처를 처음 마주했을 당시에는 이걸 왜 이렇게 만들었지? 하는 의문은 들었지만 업무 처리에 급급해 깊이 이해하는 느낌은 들지 않았다. 하지만 전체적인 그림과 히스토리를 어느 정도 알고 나서 이 책에 나온 개념들을 함께 접목해 읽어보니상황(성능적인 부분, 비용적인 부분, 운영 편의성)에 따라왜 우리 시스템은 이렇게 구성되었는가?를 이해하게 되었다. -
이 책과 현재 진행 중인 기술이 어떤 방향성을 가지고 있는지 비교하는 재미가 있다. 어느 정도 시간이 지난 책인 만큼
요즘에는 어떤 기술로 이런 문제를 핸들링하는지조금씩 찾아보면 흥미롭다. 안정성이 검증된 기술을 가능한 한 오래, 효율적으로 유지하려는 금융권 특유의 문화에서 오는 기술적 갈증이 이 책을 더 흥미롭게 만든다. -
순수하게 모르는 기초적인 내용을 알게 되는 재미다. 기술의 부분부분을 이해하거나 지엽적인 한 영역을 깊게 경험해보는 것도 의미 있지만,
핵심이 되는 기본적인 내용들을 잘 이해하는 것은 또 다른 문제임을 느꼈다. 현재 아키텍처가 최선인지 따져보려면 왜 이렇게 구성되었는지를 먼저 잘 파악해야 했는데, 그저 새로운 기술을 공부해 덕지덕지 붙여보기에 급급했던 것은 아닌지 반성하게 되었다.
앞으로 6주간의 포스팅은 ⌜빅데이터를 지탱하는 기술⌟을 다시 한 번 읽고 간단하게 정리하는 포스팅을 진행한다.
1장 핵심 내용
1장은 전체적인 기초 개념들을 훑어준다. 크게 요약하면 아래 세 가지 정도로 정리할 수 있다.
- Hadoop, NoSQL, 그리고 Data Warehouse
- 데이터 파이프라인 기본 구조와 DataLake
- 스크립트 언어(Python/DataFrame)의 효율성과 BI 도구, 모니터링
2011년 이후 데이터의 용량이 기하급수적으로 확대되면서 데이터의 양에 따라 스몰 데이터와 빅데이터로 구분되기 시작했고, 이에 대응하기 위한 아키텍처와 기술들도 결이 달라지기 시작했다. 하나의 아키텍처가 스몰 데이터와 빅데이터 모두에 비용 효율적으로 대응 가능했다면 베스트이겠지만 그것이 쉽지 않기 때문에 다양한 기술들이 등장했다.
Hadoop, NoSQL, 그리고 Data Warehouse
우선 기존의 Data Warehouse가 담당하던 기능을 Hadoop이 대체하기 시작했다.
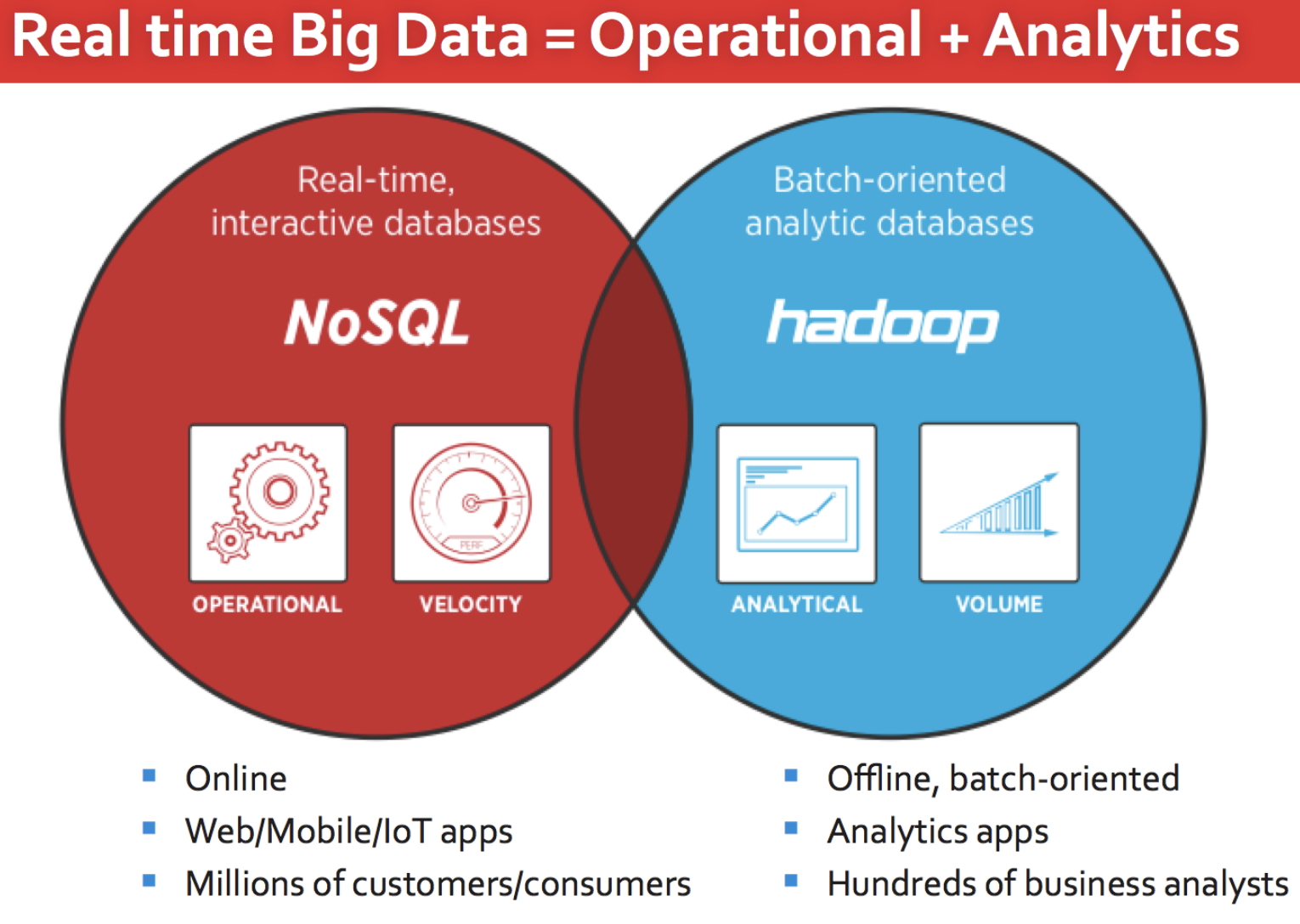
Data Warehouse는 보통 하드웨어와 소프트웨어가 결합된 상태로 제공되므로 데이터 용량이 늘어났을 때 확장하기가 쉽지 않다는 단점이 있다. 따라서 가속도적으로 늘어나는 데이터는 Hadoop으로 처리하고, 비교적 작거나 중요한 데이터는 Data Warehouse에 넣어 DW에 직접적으로 가중되는 부하를 줄이는 방식이 정착되었다.
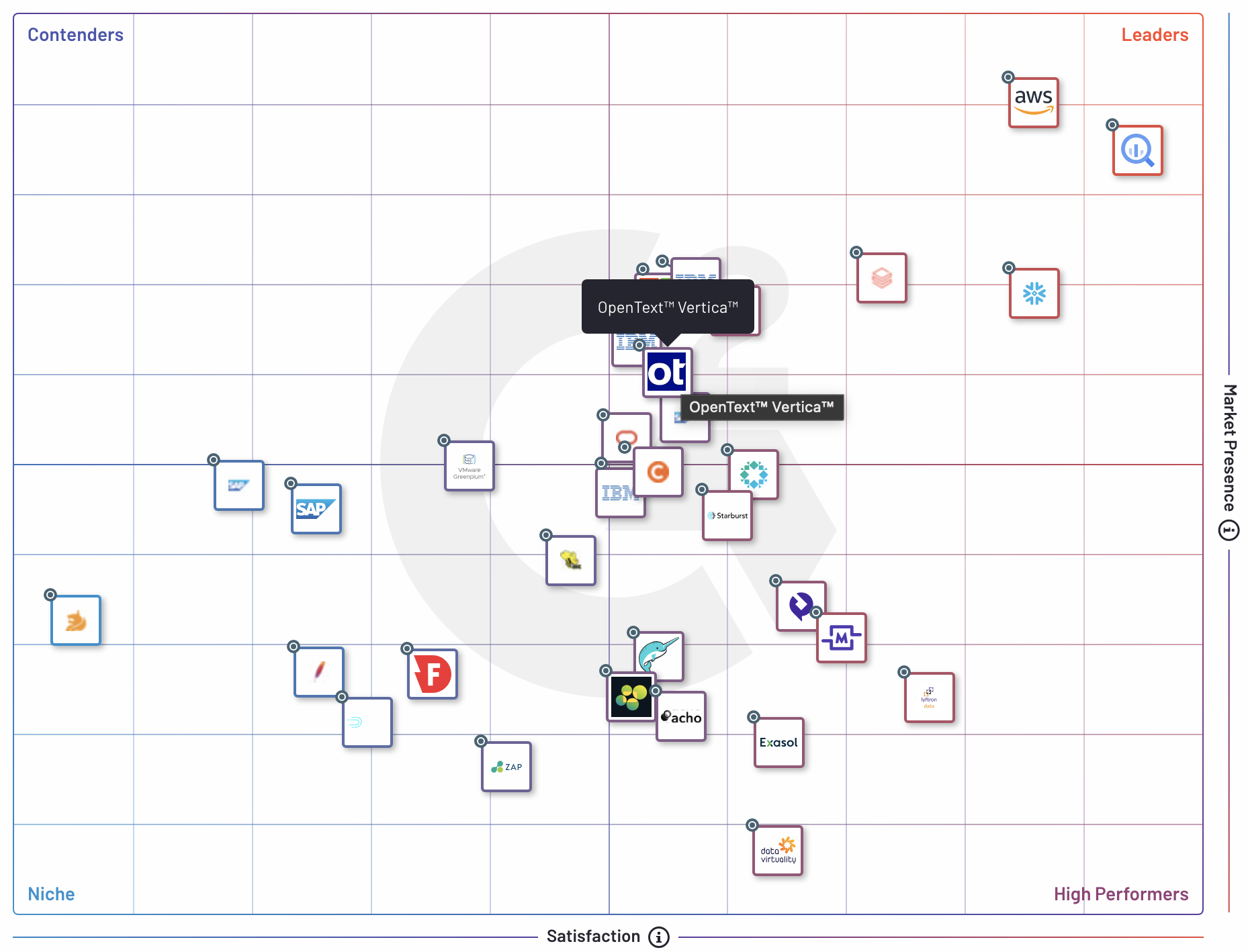
DW는 Hadoop에 비해 분명한 성능상의 장점을 가지고 있다. 현재 Data Warehouse는 클라우드 솔루션이 높은 순위를 차지하고 있으며, Tera/Vertica를 포함해 Redshift, BigQuery, Snowflake와 같이 유명한 솔루션들이 순위권에 있다.
Tip
Popular DW Solutions g2.com 에서 마켓 사이즈에 따른 그리드 차트도 함께 확인해볼 수 있다.
데이터 파이프라인 기본 구조와 DataLake
두 번째 내용은 데이터 파이프라인 구조의 변화와 관련된 부분이다. 기존에 Data Warehouse 기반으로 구축된 파이프라인이 Data Lake 중심으로 재구축되었다는 내용이다. 단계는 1) 데이터 수집, 2) 분산 스토리지에 저장, 3) 분산 데이터 처리 순이다.
데이터 수집은 기존에 벌크로 처리되던 흐름이 스트림 처리가 등장하면서 결과를 시계열 데이터베이스(TSDB, Time Series Database)에 저장하는 식으로 처리된다. 저장 단계에서는 수집된 데이터를 S3와 같은 분산 스토리지에 저장하거나 NoSQL 등에 저장한다. 마지막은 분산 데이터 처리다. 데이터 집계에 제일 익숙한 언어는 SQL이며, 이를 위해서는 Hive와 같은 쿼리 엔진(query engine)을 이용하거나, Impala, Presto 같은 대화형 쿼리 엔진(interactive query engine)을 사용한다.
Tip
시계열 데이터베이스(TSDB, Time Series Database) RDB는 인덱스가 걸려있으면 데이터의 양이 커질수록 쓰기 성능이 점점 저하되지만 TSDB의 인덱스는 이런 경우에도 성능이 떨어지지 않도록 만들어졌다. TSDB는 시간에 따라 저장공간을 분리하고 시간으로 쿼리할 수 있다.
이어지는 내용은 워크플로우 부분이다. ETL과 ELT를 구분하면 다음과 같다.
Transform하여 Load하는 방식이면 ETL(주로 Data Warehouse), 데이터를 먼저 Load하고 이후 Transform 과정을 거치면 ELT(주로 Data Lake)이라고 한다.
ETL과 ELT의 주요 차이점 5가지는 다음과 같다.
- ETL은 데이터의 추출, 변환, 로드 프로세스를 가리킨다. ELT는 데이터의 추출, 로드, 변환 프로세스를 가리킨다. 둘 다 데이터 통합을 위한 프로세스다.
- ETL에서 데이터는 데이터 소스에서 스테이징을 거쳐 데이터 웨어하우스로 이동한다.
- ETL은 민감한 보안 데이터를 정리한 후 데이터 웨어하우스에 로드하기 때문에 데이터 개인 정보 보호와 규정 준수에 도움이 된다.
- ELT는 모든 데이터를 즉각적으로 로드할 수 있고, 사용자는 변환 및 분석 대상 데이터를 추후에 결정할 수 있다.
- ELT는 변환을 기다릴 필요가 없고 데이터는 대상 데이터 시스템으로 한 번만 로드되기 때문에 데이터 로드가 더 빠르게 진행된다.
정리하며
이번 장의 내용은 다음과 같이 정리된다.
- 2011년 이후 Hadoop과 NoSQL 데이터베이스 분산 시스템이 기존의 DW(데이터 웨어하우스)를 보완·대체하기 시작했다.
- 하나의 아키텍처가
스몰 데이터와빅데이터모두에 비용 효율적으로 대응하기란 쉽지 않다. - 데이터 파이프라인은 Data Lake 중심으로 재편되었으며, ETL에서 ELT 방식으로의 전환이 이루어졌다.
참고문헌
- [출처] 니시다 케이스케(Keisuke Nishida), ⌜빅데이터를 지탱하는 기술(BIG DATA WO SASAERU GIJUTSU)⌟, 장성두 옮김, 주식회사 제이펍
- https://terrydhariwal.github.io/the_basics/2015/09/21/nosql-big-data
- https://www.g2.com/categories/data-warehouse#grid
- https://mangkyu.tistory.com/188
- https://www.integrate.io/ko/blog/etl-vs-elt-ko/
- https://cocoder16.tistory.com/83
- https://mangkyu.tistory.com/190