시작하며

Apache Spark는 원래 Hadoop YARN 환경에서 동작하도록 설계되었지만 최근에는 Kubernetes(K8s) 환경에서도 많이 사용되고 있다. 기존에 리소스 관리 도구로 YARN이 잘 갖추어져 있는데 왜 Spark on K8s가 필요하게 되었을까? 대표적으로 아래 이유들을 찾아볼 수 있었다.
-
Spark 실행 환경을 컨테이너화하여 더 쉽게 배포 및 운영 가능
- YARN 기반 Spark는 기본적으로 Hadoop 환경에 종속적이나 Kubernetes는
컨테이너기반이므로 Hadoop이 없어도 Spark를 배포할 수 있다.
- YARN 기반 Spark는 기본적으로 Hadoop 환경에 종속적이나 Kubernetes는
-
클라우드 환경 (AWS, GCP, Azure)과의 궁합이 좋음
- Spark on Kubernetes는
S3,GCS,ADLS등과 네이티브하게 연동할 수 있어 클라우드에서 훨씬 더 유리하다.
- Spark on Kubernetes는
-
오토스케일링 (Auto-Scaling) 및 리소스 최적화
- Spark on YARN의
Dynamic Allocation은 YARN의 리소스 정책 때문에 제약이 많지만 Kubernetes에서는Executor수를 자동으로 조정할 수 있고 리소스 할당이 자유롭다.
- Spark on YARN의
그 외에도 각 노드별 의존성을 배포해야 하는 YARN에 비해 DevOps 및 CI/CD 연동이 용이하다던지, 필요할 때만 실행 후 종료하는 온디맨드 클러스터 방식의 유연함 또한 Spark on K8s의 장점이라고 할 수 있으며 뱅크 셀러드나 우아한 형제들의 기술블로그에서도 각 사에서 왜 K8s 기반의 Spark 시스템으로 전환하였는지 그 이유를 찾아볼 수 있었다.
Spark on Kubernetes vs Spark on YARN
Spark on Kubernetes와 Spark on YARN의 차이
그럼 조금 더 들어가서 Spark on K8s와 Spark on YARN은 수행 방식에 어떤 점에서 차이가 있을까?
1. Spark on YARN
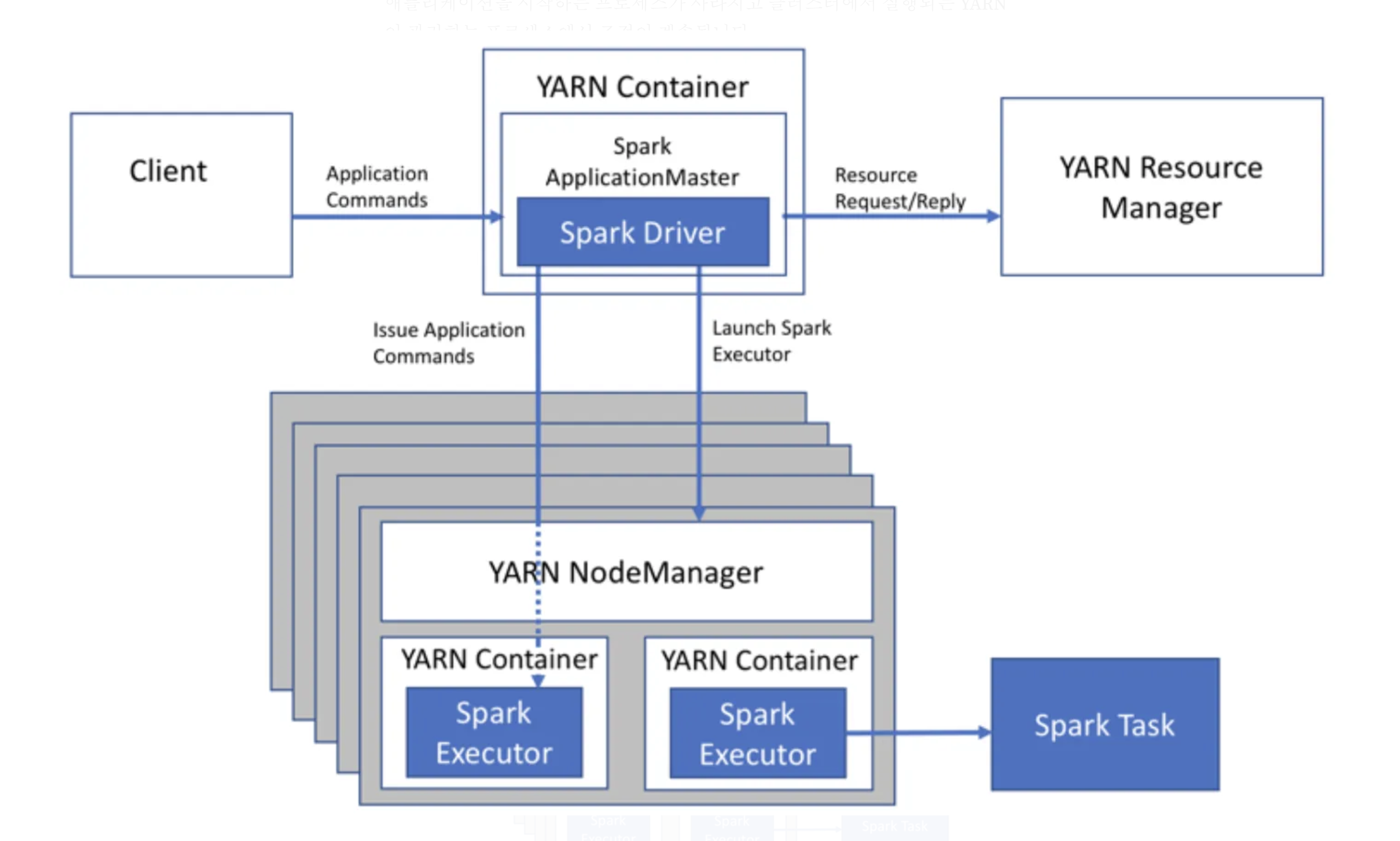
위 그림은 YARN을 통해 Spark를 사용하는 전통적인 방식이다. Spark는 YARN에서 실행하기 위한 두 가지 모드인 yarn-cluster 모드와 yarn-client 모드를 지원하지만, yarn-client 모드는 대화형 및 디버깅 용도이므로 생략한다. yarn-cluster 모드에서 드라이버 프로세스는 Application Master에서 실행된다. 즉, 동일한 프로세스가 애플리케이션을 구동하고 YARN에서 리소스를 요청하는 두 가지를 담당하며, 이 프로세스는 YARN 컨테이너 내부에서 실행된다. YARN의 NodeManager가 각 노드에서 컨테이너를 실행하고, ResourceManager가 클러스터의 리소스를 관리하게 되며, Executor는 YARN의 리소스 관리 정책에 따라 적절한 노드에서 실행된다.
2. Spark on Kubernetes
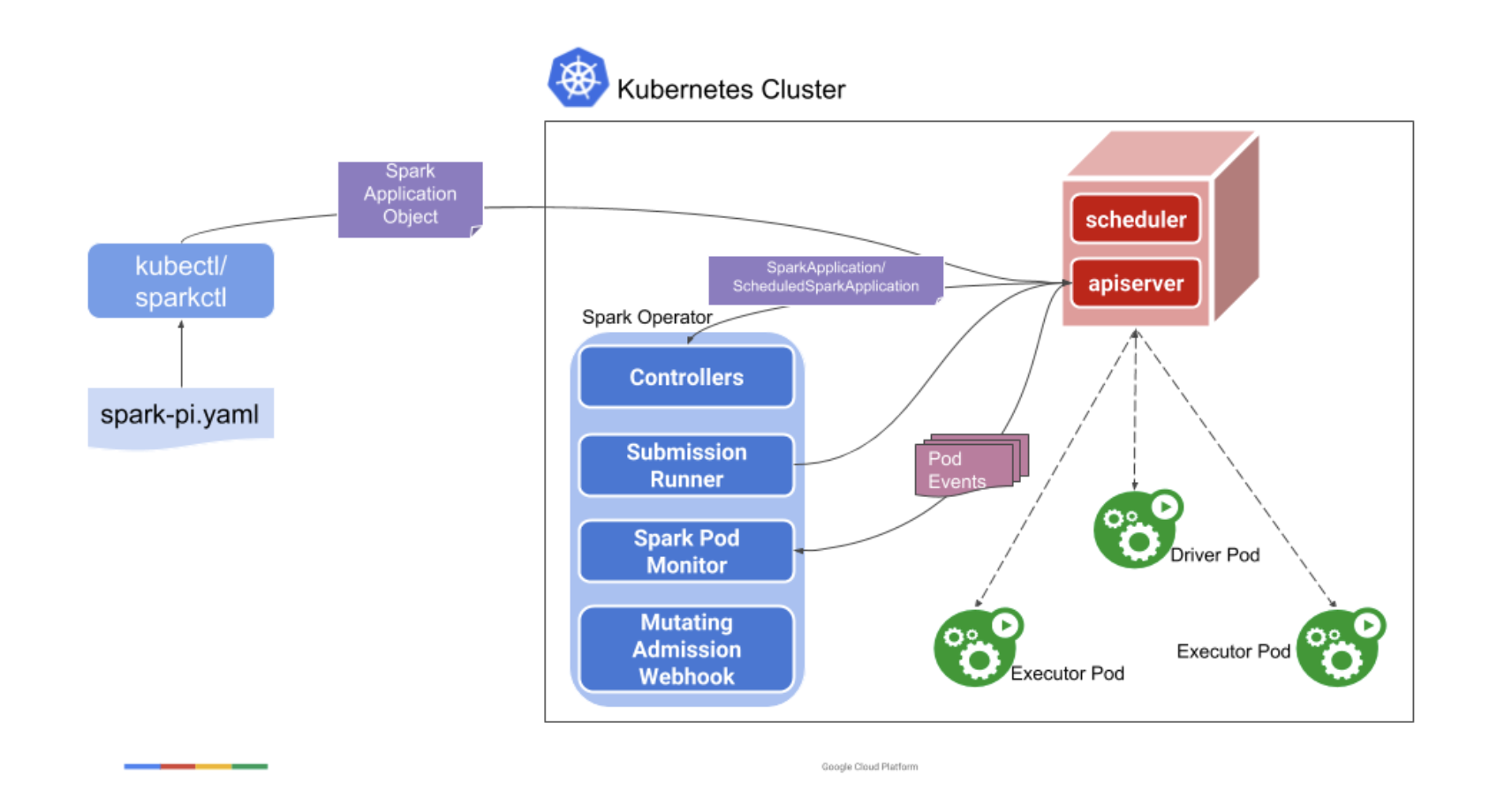
반면 Kubernetes에서의 Spark는 YARN과 완전히 다르게 동작한다. kubectl 커맨드를 통해 SparkApplication 객체가 생성되면, controller는 api-server의 watcher를 통해 객체를 인식한다. 그 후 spark-submit에 필요한 항목들을 담은 submission을 생성하고 이를 submission runner로 보낸다. submission runner는 Driver Pod를, Driver Pod는 Executor Pod를 생성하여 작업을 수행한다. Kubernetes는 자체적인 스케줄러를 사용하여 리소스를 관리하며, Driver는 Kubernetes의 Pod로 배포되고, Kubernetes API를 통해 Executor Pod들을 동적으로 생성한다.
1. Native Kubernetes Integration (spark-submit 사용)
먼저 Apache Spark의 기본 기능을 활용하여 Kubernetes에서 Spark 애플리케이션을 실행하는 방식이다. Spark 공식 도큐먼트에서 설명하는 방식이 바로 이 방법이다.
동작방식
- 사용자가 spark-submit 명령을 실행하면, Spark Driver가 Kubernetes에 직접 배포된다.
- Spark Driver는 Kubernetes API를 호출하여 Executor Pod를 생성한다.
- 실행이 끝나면 Executor Pod는 삭제된다.
- Spark 자체가 Kubernetes API를 직접 사용하여 Executor를 관리한다.
실행 예시
spark-submit \
--master k8s://https://<K8S-API-SERVER> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.container.image=<YOUR-SPARK-IMAGE> \
--conf spark.kubernetes.namespace=spark \
local:///opt/spark/examples/jars/spark-examples_2.12-3.3.1.jar 100장단점
-
추가적인 설치 없이 Spark만으로 Kubernetes에서 실행 가능
-
Spark API로 Kubernetes 리소스를 직접 관리 (간단한 설정)
-
기존 Spark Workflow와 쉽게 연계 가능
-
Pod 관리가 자동화되지 않아 Job을 여러 개 실행하면 관리가 어려움
-
spark-submit을 직접 실행해야 하므로 GitOps/CI/CD 통합이 어려움
-
Job 관리 기능 부족 (재시작, 롤백 등)
2. Spark Operator (Kubernetes CRD 활용)
두 번째 구성 방법은 Google에서 개발한 spark-on-k8s-operator를 사용하여 Spark를 Kubernetes 리소스처럼 관리하는 방식이다.
동작방식
- Spark Operator가 Kubernetes 클러스터에서 실행된다.
- 사용자는 SparkApplication이라는 Kubernetes Custom Resource Definition (CRD)를 생성한다.
- Spark Operator가 SparkApplication을 감지하고, Spark Driver 및 Executor Pod를 자동으로 생성한다.
- Spark Job이 끝나면 Pod가 자동 정리되며, Job 상태가 Kubernetes 리소스로 관리된다.
실행 예시
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: spark-pi
namespace: spark
spec:
type: Scala
mode: cluster
image: gcr.io/spark-operator/spark:v3.3.1
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.12-3.3.1.jar"
sparkConf:
"spark.executor.instances": "2"
"spark.kubernetes.namespace": "spark"
driver:
cores: 1
memory: "512m"
executor:
cores: 1
instances: 2
memory: "512m"장단점
-
Kubernetes의 CRD 방식으로 Spark Job을 Kubernetes 네이티브 방식으로 관리 가능
-
GitOps 및 CI/CD와 쉽게 통합 가능 (예: ArgoCD, Flux 등과 연계)
-
Job 재시작, 상태 저장, 스케줄링 지원
-
여러 Spark Job을 관리할 때 운영 부담이 줄어듦
-
Spark Operator를 Kubernetes 클러스터에 별도로 배포해야 함
-
Helm 또는 YAML을 작성해야 하므로 설정이 다소 복잡할 수 있음
3. Spark Cluster (Standalone Spark Cluster on Kubernetes)
마지막으로 Kubernetes에서 Spark 자체를 하나의 클러스터(Standalone Mode)로 배포하여 사용하는 방식이다. 기존의 Spark Cluster와 유사한 방식이다.
동작방식
- Spark Master Pod 및 Worker Pod를 배포하여 Spark Standalone Cluster를 Kubernetes에 구성한다.
- 사용자가 spark-submit을 실행하면 Spark Master가 이를 관리하고, Spark Worker들이 Executor 역할을 수행한다.
- 기존의 Spark Cluster처럼 Kubernetes를 리소스 프로비저닝 용도로만 사용한다.
실행 예시
# helm install
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install my-spark bitnami/spark --namespace spark
# spark submit
kubectl exec -it my-spark-master-0 -- /bin/bash
spark-submit --master spark://my-spark-master:7077 --deploy-mode client \
--class org.apache.spark.examples.SparkPi \
local:///opt/spark/examples/jars/spark-examples_2.12-3.3.1.jar 100장단점
-
기존 Spark Cluster 사용자들에게 익숙한 방식
-
Kubernetes의 리소스 관리 기능을 Spark Cluster에 적용 가능
-
Helm을 사용하여 손쉽게 설치 및 업그레이드 가능
-
Spark Job을 배포할 때마다 Master와 Worker를 관리해야 함
-
Kubernetes 네이티브 방식이 아니므로 확장성에서 다소 불리
-
Spark Operator 방식보다 GitOps, CI/CD 통합이 어려움
정리하며
이번 포스팅에서는 Spark on Kubernetes의 전체적인 개요를 알아보고자 Spark on YARN과의 차이점, 그리고 Spark on Kubernetes를 구성하기 위한 세 가지 방법인 1) Native Kubernetes Integration, 2) Spark Operator, 3) Standalone Spark Cluster에 대해 살펴보았다. 다음 포스팅에서는 Spark on Kubernetes를 조금 더 깊게 알아보고, 온-프레미스 쿠버네티스 클러스터에서 실제 Helm 등을 통해 간편하게 환경을 구축하고 Spark Job을 테스트해보도록 하겠다.
참고문헌
- https://spark.apache.org/docs/latest/running-on-kubernetes.html
- https://www.chaosgenius.io/blog/spark-on-kubernetes
- https://velog.io/@newnew_daddy/spark06
- https://medium.com/@SaphE/deploying-apache-spark-on-kubernetes-using-helm-charts-simplified-cluster-management-and-ee5e4f2264fd
- https://artifacthub.io/packages/helm/bitnami/spark
- https://github.com/kubeflow/spark-operator
- https://medium.com/@SaphE/deploying-apache-spark-on-a-local-kubernetes-cluster-a-comprehensive-guide-d4a59c6b1204