시작하며
Elasticsearch를 구축하고 운영하다 보면 어느 순간부터 예측하지 못한 여러 문제들을 마주하게 된다. 이번에는 운영 중이던 Elasticsearch 8.6 클러스터의 JVM 힙 메모리가 증가한 원인과 이를 해결하기 위한 과정을 기록한다.
Elasticsearch JVM Heap 메모리 문제 분석 및 해결
Elasticsearch 안정적으로 운영하기
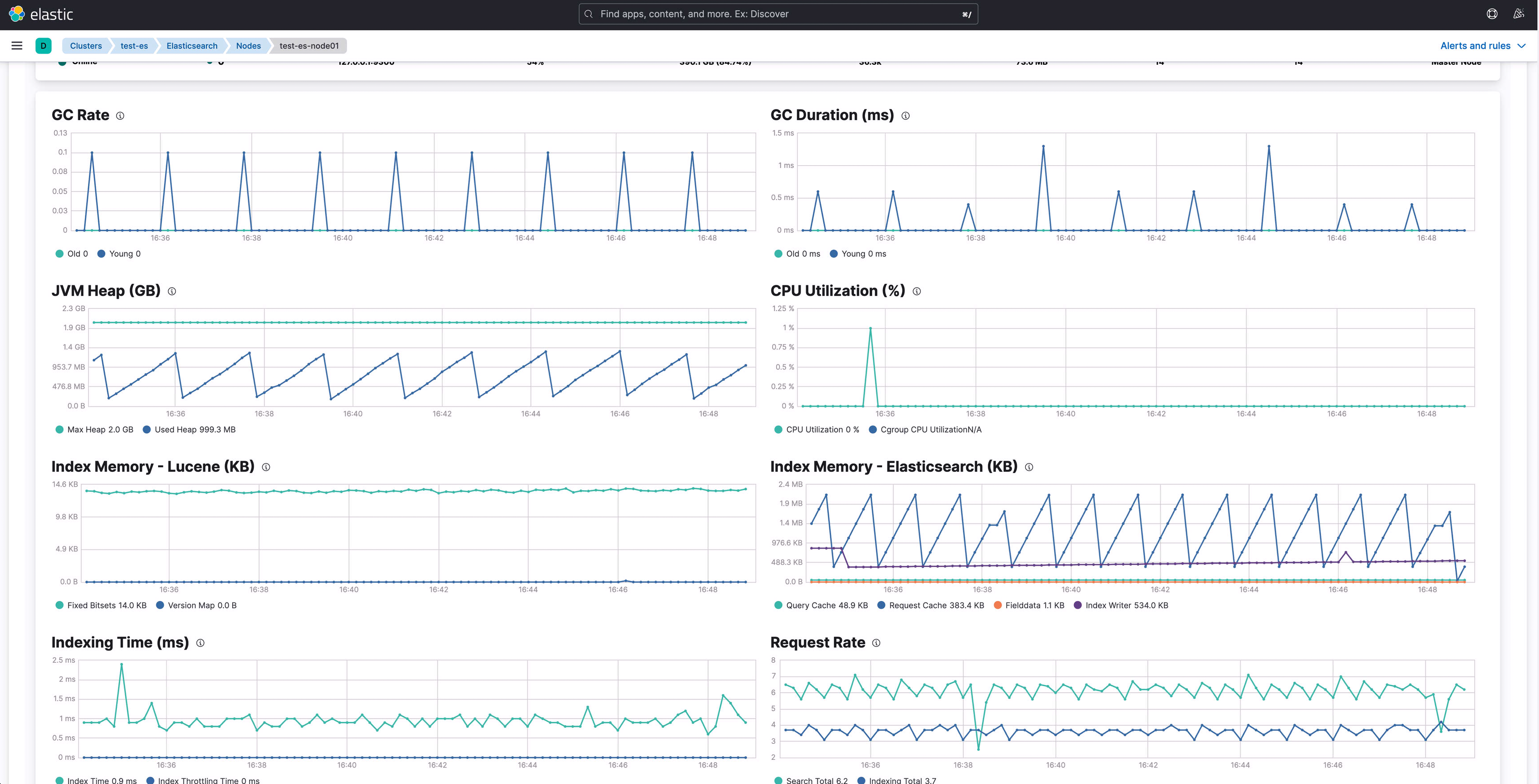
Elasticsearch 클러스터를 서비스 로그 모니터링 목적으로 구축한 지 벌써 9개월이 되어간다. 다행히 인입되는 로그의 적재량은 처음 시작하면서 예측했던 수준을 넘기지 않았는데, 아무래도 초기 설정할 당시 지정했던 샤드 개수로 인해 JVM Heap 메모리 사용률이 평시 75% 정도까지 올라갔고 특정 집계 쿼리가 필요하다거나 하는 경우에는 90% 정도까지 접근하는 경우가 생겼다. 물론 앞단에 Kafka를 두고 Logstash를 통해 데이터를 컨슘하여 적재하고 있는 구조라 문제가 생기더라도 대응할 수는 있었지만 안전한 운영을 위해서는 Elasticsearch의 안정화가 필요한 상황이었다.
Elasticsearch에서의 JVM Heap Memory

Kibana에서는 운영 중인 클러스터의 상태를 모니터링할 수 있다. JVM Heap 메모리가 증가한 시점을 기준으로 여러 메트릭을 비교해 보니 Index-Memory의 Fielddata 값이 짧은 텀에 급속하게 증가(1GB에서 5GB)한 것을 확인할 수 있었다. elastic cluster에서 사용하는 index의 필드 매핑값들은 keyword로 명시적 매핑을 적용하였고 특별히 복잡한 형태의 쿼리가 수행되는 것은 없었다. 주 단위로 수행되는 집계 배치가 있긴 했지만 배치가 수행되는 시점과 JVM Heap Memory가 증가하기 시작한 시점과는 거리가 있어 보였다. 따라서 fielddata 증가가 전체 클러스터에 영향을 미친 것이라 판단하고 해결 방법을 찾아보았다.
Info
FieldData vs DocValue Fielddata는 elasticsearch에서 색인된 문서의 특정 필드값을 메모리에 저장하는 방식이다. 메모리에 적재되어 있으므로 필드의 크기가 크고 고유한 값을 가지는 경우 메모리 소비가 높아질 수 있다. 반면 DocValue는 메모리를 효율적으로 사용하기 위해 JVM heap 메모리가 아닌 운영체제 OS의 파일 시스템 캐시를 사용해 색인 시 디스크를, 검색 시 시스템 캐시를 이용하는 디스크 기반 데이터 구조를 말한다.
Solution 1. FieldData Cache clear
제일 먼저 한 작업은 클러스터 상태를 빠르게 안정시키기 위해 Fielddata cache clear 작업을 우선적으로 진행했다. 일시적으로 heap 메모리에 부하가 발생할 수는 있지만 Index Memory의 Fielddata가 메모리를 잡아먹으면서 전체 클러스터에 영향을 주고 있었기 때문이다.
Fielddata cache clear는 다음과 같이 진행할 수 있다.
POST /my-index-000001/_cache/clear?fielddata=true Tip
Fielddata와 비슷하게, Elasticsearch에서 사용하는 cache는 다음과 같다.
- Node Query Cache - 필터 컨텍스트에 사용된 쿼리 결과는 빠른 조회를 위해 노드 쿼리 캐시에 캐시된다.
- Shard Request Cache - 샤드 수준 요청 캐시 모듈은 각 샤드의 로컬 결과를 캐시하며 자주 사용되는 검색 요청의 결과를 반환한다.
- Field Data Cache - 검색 결과에 포함된 문서를 빠르게 접근하기 위한 캐시이며 주로 필드에서 aggregation 연산을 수행할 때 사용한다. 단, Field Data Cache는 할당량을 제한하더라도 작동 방식이 먼저 메모리에 데이터를 올리고 제한을 넘으면 사용되지 않는 데이터를 제거하는 방식이기 때문에 OOM 에러가 발생할 수 있다.
Solution 2. Reindexing을 통한 샤드 개수 축소
사실 Fielddata cache clear만으로도 Cluster는 정상화되었고 할당되지 않은 shard들이 정리되기 시작했다. 하지만 Cache clear를 주기적으로 반복하는 것은 올바른 해결책이 아닌 임시방편일 뿐이고, 결론적으로 샤드 개수를 조정하기로 했다. 프라이머리 샤드의 개수는 한 번 지정되고 나면 변경이 불가능하므로 아예 새로운 인덱스를 생성하는 reindex API를 통해 인덱스를 재생성한다.
Tip
적절한 샤드 개수는 몇 개일까? 노드에 저장할 수 있는 샤드의 개수는 가용한 힙의 크기와 비례하지만, Elasticsearch에서 그 크기를 제한하고 있지는 않는다. 경험상으로 보면 노드의 샤드 개수를 하나의 노드에 설정한 힙 1GB당 20개 미만으로 유지하는 것이 좋다. 따라서 힙이 30GB인 노드는 최대 600개의 샤드를 가질 수 있지만 이보다 훨씬 더 적게 유지하는 것이 더 좋다. … elastic 블로그 참조
shard reindexing은 다음과 같이 진행할 수 있다.
- 테스트 reindex를 생성한다.
POST test_reindex_source/_doc
{
"test": "test"
}- 설정, 매핑 및 원하는 샤드 수를 사용하여 대상 인덱스를 생성한다.
PUT test_reindex_target
{
"mappings" : {},
"settings": {
"number_of_shards": 10,
# number_of_replicas 0, refresh_interval -1 로 설정하면 reindexing 속도가 빨라진다.
"number_of_replicas": 0,
"refresh_interval": -1
}
}- reindexing 프로세스를 시작한다.
requests_per_second=-1및slices=auto를 설정하면 reindexing 속도가 조정된다.
POST _reindex?requests_per_second=-1&slices=auto&wait_for_completion=false
{
"source": {
"index": "test_reindex_source"
},
"dest": {
"index": "test_reindex_target"
}
}- reindexing이 완료된 후 설정을 업데이트한다.
PUT test_reindex_target/_settings
{
"number_of_replicas": 1,
"refresh_interval": "1s"
}Solution 3. Kibana Visualization 점검
마지막으로는 Kibana Visualization을 점검하는 방법이 있다. 서비스 운영에 꼭 필요하다고 생각하는 부분들 위주로 화려하게 대시보드를 꾸몄지만 사실 몇 달 운영을 해 보니 쓸모없는 뷰들이 눈에 들어왔다. 서비스 운영에 꼭 필요한 뷰들만 남기고, 기존의 Visualization을 깔끔하게 가지치기하는 것만으로도 클러스터 안정성에 도움을 줄 수 있다.
정리하며
지금까지 Elasticsearch 클러스터 운영 중 발생한 JVM Heap 메모리 사용률 초과 상황에 대한 해결 방법을 알아봤다. 적절한 샤드 개수와 크기를 파악해서 적절하게 잘 유지하는 것은 딱 정해진 방법이 없어 더 까다롭다. 다음 포스팅에서는 샤드의 개수와 크기를 적절하게 세팅하는 방법에 대해 이어서 알아본다.
참고문헌
- https://www.elastic.co/kr/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
- https://www.elastic.co/guide/en/elasticsearch/reference/8.6/size-your-shards.html#shard-size-recommendation
- https://www.elastic.co/guide/en/elasticsearch/reference/8.6/size-your-shards.html#field-count-recommendation
- https://www.elastic.co/guide/en/elasticsearch/reference/current/circuit-breaker.html
- https://toss.tech/article/slash23-data
- https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-reindex.html
- https://opster.com/guides/elasticsearch/operations/how-to-increase-primary-shard-count-in-elasticsearch/