시작하며
이번 포스팅은 빅데이터분석기사 시험을 준비하며 공부했던 내용들을 공유하는 글이다.

- 시험 난이도 : 중
- 준비 시간 : 약 10일 (평일 2시간, 주말 4시간)
필기 시험 준비 내용
PART1. 빅데이터 분석 기획 (기본 개념)
- (상) 빅데이터 개요 및 활용
- 가트너 3V : Volume(규모), Variety(다양성), Velocity(속도), +Veracity(품질), +Value(가치)
- 빅데이터 활용 3요소 : 자원(빅데이터), 기술(빅데이터플랫폼, AI), 인력(알고리즈미스트, 데이터사이언티스트)
- 정보의 특징 : 정확성, 적시성, 적당성, 관련성 (일관성은 아님)
- 지식 창조 메커니즘 단계 : 공통화(인식 공유하여 암묵지로) - 표출화(암묵지가 구체화되어 형식지로) - 연결화(형식지를 재분류하여 체계화) - 내면화(전달받은 형식지를 개인의 것으로)
Info
암묵지) 학습과 경험을 통하여 개인에게 체화되어 있지만 겉으로 드러나지 않은 지식 형식지) 형식을 갖추어 표현되고 공유가 가능한 지식
- DW 구성요소 : 데이터 모델, ETL, ODS(다양한 DBMS 통합 관리), Meta-Data, OLAP, 데이터마이닝, 분석 TOOL & 경영 기반 솔루션(BI)
Info
데이터 웨어하우스 특징 : 주제 지향성(Subject-Orientation), 통합성(Integration), 시계열성(Time-variant), 비휘발성(Non-volatilzation)
- 조직의 구성 : 집중형(전사 분석 업무를 별도의 전담 조직-DSCoE에서 수행), 기능형(각 부서에서 분석 업무를 직접 수행), 분산형(분석 전문 인력-DSCoE을 현업 부서에 배치하여 분석 업무 수행)
Info
DSCoE : Data Science Center of Excellence - 분석 전담 조직
- (상) 빅데이터 기술 및 제도
- 빅데이터 플랫폼 기능 : 컴퓨팅 부하 → (클러스터 자원 할당), 저장 부하 → (메모리 파일 시스템), 네트워크 부하 → (최단 거리 노드 탐색, 대역폭 분배)
- 빅데이터 3계층 : 소프트웨어 계층(데이터 수집 정제 처리 등), 플랫폼 계층(작업 스케줄링, 자원 할당), 인프라스트럭처 계층(스토리지 관리, 네트워크 배치 & 관리)
- 빅데이터 처리 과정 : 데이터 생성 → 수집(crawling, 로그, sensor, openapi, ETL) → 저장(NoSQL, HDFS, S3, NAS 등) → 처리(HADOOP, SPARK, MapReduce) → 분석(분류, 군집화, 머신러닝, 데이터마이닝, 감정 분석 등) → 시각화
Info
- RDBMS 트랜잭션 속성 : 원자성(Atomicity), 일관성(Consistency), 독립성(Isolation), 지속성(Durability)
- MapReduce 단계 : Split → Map → Shuffle → Reduce
- 분석 분류 : 탐구 요인 분석(EFA: 데이터 간 상호관계), 확인 요인 분석(CFA: 변수들의 집합 요소 구조 파악)
- 머신러닝 분류
- 지도 학습(Supervised Learning) : 분류, 회귀
- 비지도 학습(Unsupervised Learning) : 군집, 오토 인코더 → 이상 징후 탐지, 노이즈 제거, GAN(생성적 적대 신경망) → 생성자는 가짜 사례를 생성, 감별자는 진위 판별하는 식으로 공방 반복
- 준지도 학습(Semi-supervised Learning)
- 강화 학습(Reinforcement Learning)
- 데이터 3법
- 개인정보보호법/일반법 : 당사자의 동의 없이 개인 정보의 수집, 활용을 금지 → 개인 정보를 구체적으로 개인 정보, 가명 정보(도압), 익명 정보로 구분
- 정보통신망법/특별법-우선적용 : 이용자의 동의 필요, 개인 정보 위탁 시 동의 필요 → 개인 정보 관련 사항을 개인 정보 보호법으로 이관
- 신용정보보호법 : 개인 신용 정보를 타 회사 등에 제공하고자 하는 경우에는 서명 및 동의가 필요하다 → 가명 정보는 신용 정보 주체의 동의 없이 이용 가능하다.
- GDPR : 유럽 의회에서 유럽 시민들의 개인 정보 보호 강화를 위해 만든 규정이다.
- 비식별화 : 개인을 식별할 수 있는 요소를 전부 삭제하거나 대체하여 개인 식별이 불가하도록 만든다.
- 사전 검토 → 비식별 조치 → 적정성 평가 → 사후 관리
- (상) 분석 방안 수립
- 데이터 분석 기획 : 실제 분석을 시행하기에 앞서 분석을 수행할 과제의 정의 및 방안을 사전에 계획한다.
- 분석 기획의 절차 : 비즈니스 이해 범위 설정 → 프로젝트 정의 → 수행 계획 수립 → 위험 계획 수립
- 목표 시점에 따라 : 단기적 접근 방식(과제 중심적 접근), 중장기적 접근 방식(마스터플랜 접근), 혼합 방식(분석 기획 시)
- 분석 문제 정의
- 하향식 접근 : 문제가 먼저 주어지고 이에 대한 해법을 찾아간다.
- 상향식 접근 : 문제 정의가 어려운 경우, 데이터 기반으로 문제를 재정의 및 해결 방안을 탐색한다.
- 분석 방법론 :
- KDD : 통계적인 패턴이나 지식을 탐색할 수 있는 데이터 마이닝 프로세스 → 데이터 선택 → 전처리 → 변환 → 마이닝 → 결과 평가
- CRISP-DM : 데이터 탐색을 바탕으로 비즈니스에 맞게 마이닝을 반복적으로 실시 → 업무 이해 → 데이터 이해 → 준비 → 모델링 → 평가 → 전개(배포)
- SEMMA : 기술 통계 중심의 데이터 마이닝 프로세스 → 추출 → 탐색 → 수정 → 모델링 → 평가
- 데이터 거버넌스 : 데이터 분석 업무를 하나의 기업 문화로 정착하고 지속적으로 고도화해 나간다.
- 주요 관리 대상은 마스터 데이터, 메타 데이터, 데이터 사전이다.
- 데이터 분석 수준 진단 :
- 분석 준비도 : 총 6가지 영역 대상으로 현재 수준을 파악한다.
- 분석 성숙도 : 비즈니스 부문, 조직 및 역량 부문, IT 부문 총 3개를 대상으로 실시한다.
- 도입 → 활용 → 확산 → 최적화
- (하) 분석 작업 계획
- 데이터 분석 영역 : 데이터를 추출, 가공한 후 분석을 수행하고 결과를 표현한다.
- 데이터 확보 시 분석 변수 점검 항목 : 데이터 적정성, 가용성, 기술적 타당성
- (하) 데이터 수집 및 전환
- 데이터 비식별화 : 개인 정보를 식별할 수 있는 값들을 몇 가지 정해진 규칙으로 대체하거나 가공하여 개인을 식별할 수 없게 가공한다.
- 적정성 평가 : 프라이버시 보호 모델 중 최소한으로 k-익명성, 필요 시 l-다양성, t-근접성
- k-익명성 : 특정인 추론 가능한지 검토. 동일 값을 가진 레코드를 k개 이상으로 유지한다.
- l-다양성 : 민감한 정보의 다양성을 높인다. 각 레코드는 l개 이상의 다양성을 가진다.
- t-근접성 : 민감한 정보의 분포를 낮춘다. 전체 정보 분포와 특정 분포 차이를 t 이하로 유지한다.
- 적정성 평가 : 프라이버시 보호 모델 중 최소한으로 k-익명성, 필요 시 l-다양성, t-근접성
- (하) 데이터 적재 및 저장
- CAP 이론 : 분산 컴퓨팅 환경의 특징을 일관성(Consistency), 가용성(Availability), 지속성(Partition-Tolerance) 3가지로 정의한다. 어떤 시스템이든지 이 세 가지 특성을 동시에 만족하기는 힘들다.
- 일관성(Consistency) : 분산 환경에서 모든 노드가 같은 시점에 같은 데이터를 보여 준다.
- 가용성(Availability) : 일부 노드가 다운되어도 다른 노드에 영향을 주지 않아야 한다.
- 지속성(Partition-Tolerance) : 데이터 전송 중에 일부 데이터를 손실하더라도 시스템은 정상 동작해야 한다.
- CAP에 따른 RDBMS vs NoSQL
- RDBMS : (Consistency + Availability) - 트랜잭션 ACID 보장 (ex: 금융 서비스)
- NoSQL : (Consistency or Availability 중 1개) + Partition Tolerance
- Consistency + Partition-Tolerance : 대용량 분산 파일 시스템 (ex: Bigtable, HBase)
- Availability + Partition-Tolerance : 비동기식 서비스 (ex: Dynamo, Cassandra)
Info
NoSQL의 기술적 특성
- 스키마리스, 2) 탄력성(시스템 일부에 장애가 발생해도 시스템에 접근 가능하다)
- 질의 가능, 4) 캐싱(대규모 질의에도 고성능 응답속도를 제공할 수 있는 메모리 기반 캐싱 기술 적용이 중요하다)
- NoSQL 종류별 구분
- Key-Value 데이터베이스 : 키-밸류 기반으로 확장성과 질의 응답 시간이 뛰어나다. AWS DynamoDB, Redis와 같은 In-Memory Database가 대표적이다.
- Column-Oriented 데이터베이스 : 데이터를 row가 아닌 column 기반으로 저장하며, 확장성을 보장하기 위해 여러 노드로 분할 저장된다. Google BigTable, Cassandra, HBase가 대표적이다.
- Document 데이터베이스 : 문서 형식의 정보를 저장, 검색, 관리하기 위한 DB다. MongoDB, CouchDB가 대표적이다.
PART2. 빅데이터 탐색 (약간의 수학)
- (상) 데이터 정제
- 결측 데이터의 종류
- MCAR(Missing Completely At Random) : 완전 무작위 결측, (결측 데이터가) 다른 변수와 아무 연관이 없는 경우
- MAR(Missing At Random) : 무작위 결측, (결측 데이터가) 관측된 다른 변수와 연관되어 있지만 비관측값들과는 연관 없는 경우
- NMAR(Not Missing At Random) : 비 무작위 결측, MCAR, MAR가 아닌 결측 데이터
- 데이터 이상값(Outlier) 탐지
- 시각화(Box Plot, Scatter Plot)를 통한 방법(비모수, 단변량)
- Z-score(모수, 단변량)
- DBSCAN(Density Based Spatial Clustering of Application with Noise) : 군집 간의 밀도를 이용하여 특정 거리 내의 데이터 수가 지정 개수 이상이면 군집으로 정의한다.
- Isolation Forest : Decision Tree 기반으로 정상치의 단말 노드보다 이상치의 단말 노드에 이르는 길이(Path Length)가 더 짧은 성질을 이용한다.
- (상) 분석 변수 처리
- 변수의 선택 방법 :
- 전진 선택법(Forward Selection) : 유의미한 변수를 선택해 나간다.
- 후진 선택법(Backward Selection) : 설명력이 떨어지는 변수를 소거해 나간다.
- 단계적 선택법(Stepwise Selection) : 전진 선택과 후진 선택을 반복하여 유의한 변수가 없을 때까지 진행한다.
- (중) 데이터 탐색 기초
- 박스플롯, 산점도, 상관계수, median, 표본 추출, 왜도, 기초 통계량, 이상치
- (중) 고급 데이터 탐색
- 주성분 분석, 비정형 데이터
- (중) 기술 통계
- 전수 조사, 불량률, 확률 계산, 층화 추출, 확률 분포, 포아송 분포, 중심 극한 정리, 군집 추출, 층화 추출, 카이제곱, 확률 밀도 함수
- (중) 추론 통계
- 최대 우도, Z 계산, 점 추정, 1종/2종 오류, 유의 수준, 표본 분산
PART3. 빅데이터 모델링 (모델링 알고리즘)
- 분석 절차 수립
- 모델링 절차
- 분석 환경 구축
- K-fold 검정, 데이터 분할
- (상) 분석 기법
- 회귀분석(중요)
- 로지스틱 회귀분석(중요)
- 변수 선택, 인공 신경망, 합성곱 계층, 잔차 진단, SVM, LASSO, 로지스틱 회귀, 앙상블, 비지도 학습, 지도 학습 분류, 군집 분석, 활성화 함수, 의사 결정 나무, DNN, CNN, RNN, 초매개변수
- (상) 고급 분석 기법
- 자료 분석, 다차원 척도, 베이즈 정리, 시계열 자료, 자기 상관, 비정형 데이터 형태, 랜덤 포레스트, 비모수적 통계 검정법, 배깅, 부스팅, ARIMA
PART4. 빅데이터 결과 해석 (시각화)
- (상) 분석 모형 평가
- 분류 성능
- 정확도(Accuracy) = 전체 맞힘/전체 = TP + TN / TP + FP + FN + TN
- 민감도, 재현율(Sensitivity, Recall) = T 맞힘/실T = TP / TP + FN
- 특이도(Specificity) = F 맞힘/실F = TN / FP + TN
- 정밀도(Precision) = T 맞힘/예T = TP / TP + FP
- F1 Score = 2 x 정밀도 x 재현율 / 정밀도 + 재현율
- (상) 분석 모형 개선
- 초매개변수, 모형 선택, 매개변수 최적화
- 분석 결과 해석
- MAE, MAPE, 선형 회귀, ROC, 지지도, 신뢰도
- (상) 분석 결과 시각화
- 인포그래픽(중요)
- 산점도, 막대 그래프
- 분석 결과 활용
- 모델링 타입, 분석 결과의 활용, 성과 지표
실기 시험 준비 내용
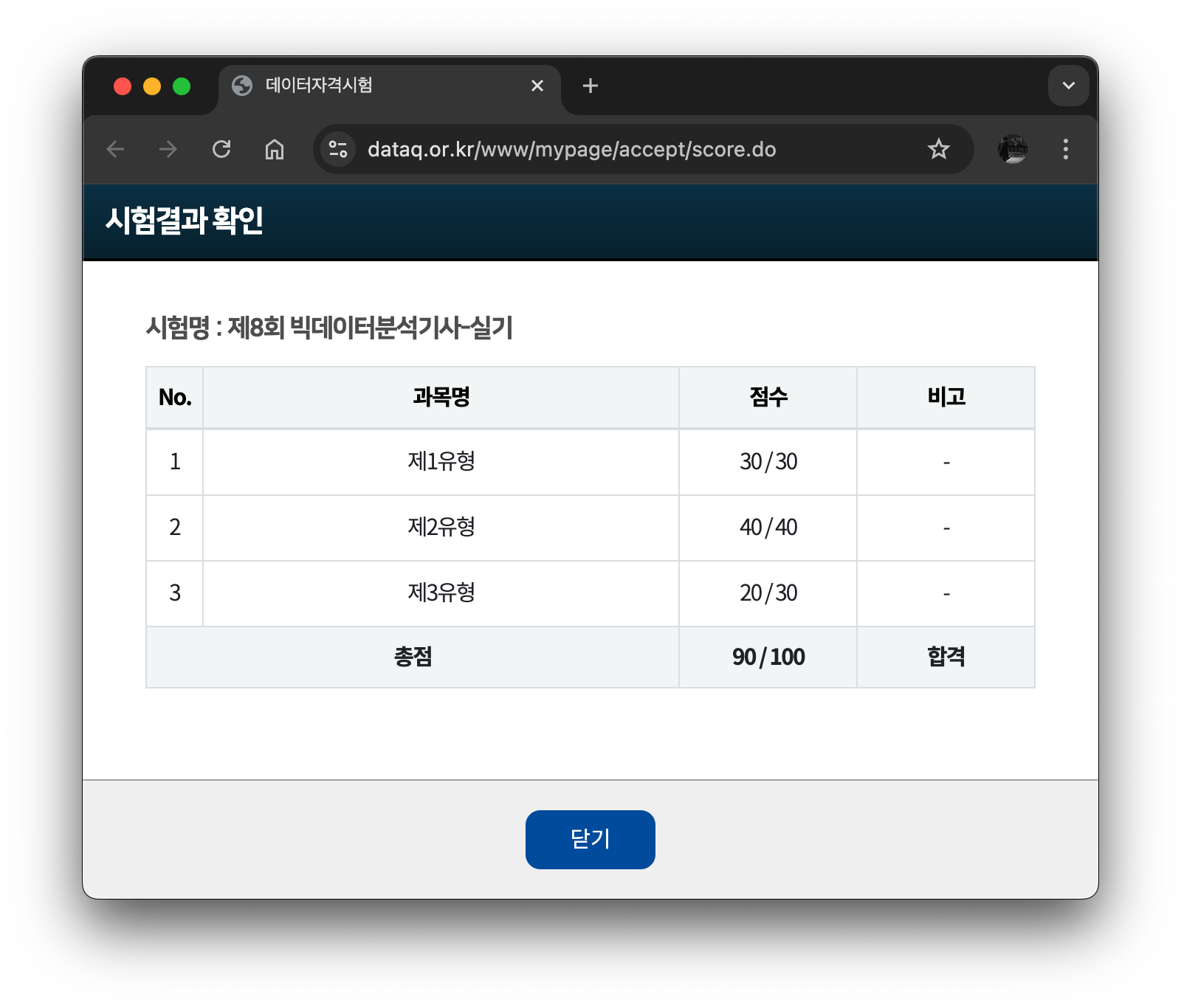
실기 시험 역시 기본적인 예제만 잘 숙지하면 크게 어렵지 않게 통과할 수 있다.
PART1. 빅데이터 분석 기사 실기 - 제1유형
- series가 여러 개 모인 것이 dataframe이다. 하지만 series와 dataframe이 제공하는 함수가 다르기 때문에 타입을 잘 선택해야 한다.
import numpy as np
import pandas as pd
# 데이터 생성 - Series
sr = pd.Series([1,2,3,4])
# 데이터 생성 - DataFrame
df = pd.DataFrame(
{
'A' : 10,
'B' : [1,2,3,4],
'C' : [11111,2,3,4],
'E' : sr
}
)
# 파일 읽기
df_from_excel = pd.read_csv('data/iris.csv')
# 파일 쓰기 -> 2유형 파일 제출, index 는 false!!
df_iris.to_csv('./data/iris_1.csv', index=False)
# 데이터 정보 보기 - 기본
df.head()
df.index
df.columns
df.T
df.to_numpy() # 배열 전환
df.describe()
df.info() # 시리즈별 타입을 확인함
# 데이터 정보 보기 - 통계
df_iris.isnull().sum() # 결측치 확인법
df_iris['variety'].isnull().sum()
dpct = df_iris['variety'].duplicated() # `duplicated()` 메서드는 각 행에 대해 이전에 등장한 동일한 값이 있는지 여부를 Boolean 값으로 반환
df_iris['variety'].unique()
df_iris['variety'].value_counts() # 각 데이터별 카운트 세어줌
df_iris.count()
df_iris.min(numeric_only=True)
df_iris.max(numeric_only=True)
df_iris.quantile(numeric_only=True) # 분위수
df_iris.sum(numeric_only=True)
df_iris.mean(numeric_only=True) # 평균
df_iris.median(numeric_only=True) # 중앙값
df_iris.var(numeric_only=True) # 분산
df_iris.std(numeric_only=True) # 표준편차
df_iris.skew(numeric_only=True) # 왜도 (왜도가 양수이면 오른쪽으로 꼬리가 긴 분포)
df_iris.kurtosis(numeric_only=True) # 첨도
# 데이터 정보 보기 - 상관계수(두 변수 간의 선형 관계의 강도)
df_iris.corr(numeric_only=True)
df_iris.corrwith(df_iris['sepal_length'], numeric_only=True) # 칼럼 선택하여 상관계수 표현
# 데이터 선택하기
# 1. subset : 부분집합 만들기
df[ 'A' ] # 한 개 컬럼만 뽑는 것. Series로 뽑힘. df[ ['A'] ] 로 넘기면 DataFrame으로 반환함.
df[ ['A','B'] ] # 여러 칼럼을 뽑으려면 리스트로 넘겨야 한다.
df[0:4] # 0 ~ 3 행까지
df[df['A'] < 0] # 조건 주는 법
# 2. loc : [행의 조건 : 열의 조건]
df.loc[:, ['A','B']] # 단 행의 조건은 생략 불가
df.loc[(df['A'] < 0) & (df['B'] > 0), ['A','B']]
# 3. iloc # loc 와 동일하나, 인덱스 중심으로 계산
df.iloc[0:4, 1:4]
# 데이터 변경하기
df1.drop('A', axis=1, inplace=True)
# 변수 타입 바꾸기
df1.astype({'B': 'int64'})
# 데이터 변환하기
df2 = df_iris.copy()
df2['variety'] = df2[['variety']].replace({'Setosa':0, 'Versicolor':1, 'Virginica':2})
# 범주화
df1 = df.copy()
df1['New_A1'] = pd.cut(df1['A'], 4, labels=False)
df1['New_A2'] = pd.cut(df1['A'], [-3,-1,0,1,3], labels=[1,2,3,4])
# Set_index, Reset_index
df1 = df.copy()
df1.reset_index(inplace=True) # 인덱스를 제외함
df1.set_index(['A'], inplace=True) # 인덱스를 넣어줌
# sort
df.sort_index(axis=1, ascending=False) # 인덱스로 정렬, axis가 1이면 열을 정렬
df.sort_values(by='A', ascending=False) # 값으로 정렬
# 인코딩
df2 = df_iris.copy()
df2['variety_label'] = pd.Categorical(df2['variety']).codes
df2 = pd.get_dummies(df2)
# 결측치 채움
df1['A'] = df1['A'].fillna(0)
# 결측치 버림
df1.dropna(subset=['A'], inplace=True)
# 중복 제거
df_iris['variety'].unique()
df2 = df_iris.copy()
df2.drop_duplicates(subset=['variety'], inplace=True)
# group by
tips.groupby('day').mean(numeric_only=True)
tips.groupby(['day', 'smoker']).mean(numeric_only=True)
# 각기 다른 집계
tips.groupby('day')[['total_bill','tip']].agg({'total_bill':'sum','tip':'mean'})
# merge
pd.merge(left, right, on='key1')
pd.merge(left, right, on='key1', suffixes=('_left', '_right'))
# Concat
pd.concat([df1, df2], axis=1, join='outer')
pd.concat([df1, df2], axis=1, join='inner')
# Reshaping
# Pivot: Long format data --> Wide format data
# Melt: Wide format data --> Long format data
df1.pivot_table(index='date', columns='item', values=['value'], aggfunc=['sum'])
df2.melt(id_vars='date', var_name='item', value_name='value1')from sklearn.preprocessing import StandardScaler, MinMaxScaler
zscaler = StandardScaler()
df['mpg_z'] = zscaler.fit_transform(df[['mpg']])
mscaler = MinMaxScaler()
df['wt_m'] = mscaler.fit_transform(df[['wt']])PART2. 빅데이터 분석 기사 실기 - 제2유형
작업 흐름
- 데이터 읽기
- 데이터 탐색
- 데이터 전처리 (처음에는 기본적인 것만)
- 필요없는 컬럼 삭제
- 결측치 처리
- 범주형 변수 : 인코딩
- 수치형 변수 : 스케일링
- 데이터 분리
- 모델 생성 - 랜덤포레스트 or XGBoost 로 통일
- 학습
- 예측
- 평가
- 최종 결과값 예측 및 제출
# 1. 데이터 읽기
import numpy as np
import pandas as pd
df_wine = pd.read_csv('data/wine.csv')
# 2. 데이터 탐색
df_wine.shape
df_wine.info()
df_wine.describe()
# 3. 데이터 전처리
df_wine.isnull().sum()
# 4. 데이터 분리
from sklearn.model_selection import train_test_split
X_col = []
y_col = []
X_train, X_test, y_train, y_test = train_test_split(df[X_col], df[y_col])
# 5. 모델 생성
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
# 6. 학습
model.fit(X_train, y_train)
# 7. 예측
pred = model.predict(X_test)
# 8. 평가
from sklearn import metrics
print(metrics.classification_report(y_test, pred))
print(round(metrics.accuracy_score(y_test, pred),2))PART3. 빅데이터 분석 기사 실기 - 제3유형
t 검정 (t-test)
- 단일 표본(표본 하나)에서의 t 검정
from scipy import stats
mu = 149
alpha = 0.05 # 유의 수준
t_statistic, p_value = stats.ttest_1samp(df['신장'], mu, alternative='two-sided')
print('t-statistic:', round(t_statistic,2))
print('p-value:', round(p_value,2))- 대응 표본(표본 한 쌍)에서의 t 검정
from scipy import stats
alpha = 0.05 # 유의 수준
df['diff'] = df['사후체력'] - df['사전체력']
print('평균차이:', round(df['diff'].mean(),2))
t_statistic, p_value = stats.ttest_rel(df['사후체력'], df['사전체력'], alternative='greater')
print('t-statistic:', round(t_statistic,2))
print('p-value:', round(p_value,2))- 독립 표본(서로 다른 표본)에서의 t 검정
from scipy import stats
alpha = 0.05 # 유의 수준
t_statistic, p_value = stats.ttest_ind(group1, group2, equal_var=True, alternative='two-sided')
print('t-statistic:', round(t_statistic,2))
print('p-value:', round(p_value,2))분산 분석
# 등분산 검정
from scipy import stats
statistic, p_value = stats.levene(group_A, group_B, group_C, group_D, center='mean')
print('statistic:', round(statistic,2))
print('p-value:', round(p_value,2))# One-way ANOVA
import statsmodels.formula.api as smf
from statsmodels.stats.anova import anova_lm
model = smf.ols('판매실적 ~ C(교육방법)', df)
result = model.fit()
anova_lm(result)# 사후 분석 Post-hoc: Tukey HSD
from statsmodels.sandbox.stats.multicomp import MultiComparison
res = MultiComparison(df['판매실적'], df['교육방법']).tukeyhsd(alpha=0.05)
res.summary()카이제곱 검정
# 적합도 검정
import scipy.stats as stats
total = len(df['항암제'])
val1 = df['항암제'].value_counts().to_list()
val2 = [total*0.7, total*0.1, total*0.05, total*0.15]
statistic, p_value = stats.chisquare(val1, val2)# 독립성 검정
from scipy import stats
obs = pd.crosstab(index=df['세탁기크기'], columns=df['가족규모'])
statistic, p_value, dof, expected = stats.chi2_contingency(obs)
print(round(statistic,2))
print(round(p_value,2))
print(dof) # 자유도 = (행-1)*(열-1)다중 회귀 분석
import statsmodels.formula.api as smf
model = smf.logit('성별 ~ 외관 + 편의성 + 유용성 + 만족감', df)
result = model.fit()
print(result.summary())상관 분석
from scipy.stats import pearsonr
r, p_value = pearsonr(df['외관'], df['만족감'])
print(round(r, 2))
print(round(p_value, 2))
n = len(df)
r2 = r**2
statistic = r * ((n-2)**0.5) / ((1-r2)**0.5)
print(round(statistic, 2))참고 자료
정리하며
여기까지 빅데이터분석기사 시험을 준비하며 공부한 내용을 공유했다. 필기는 개념 위주로, 실기는 pandas와 sklearn의 주요 API를 손에 익혀 두는 것이 핵심이다. 기본 예제만 잘 숙지하면 충분히 합격할 수 있다.